





Designing Production-Grade AI App Architectures with RAG + Agents

- What Is RAG in AI Applications
- Why RAG Alone Is Not Enough
- Core Components of AI Architecture
- Role of AI Agents in Modern Systems
- Designing the Retrieval Layer (Vector DBs)
- Context Engineering and Token Management
- Orchestration Layer and Decision Engines
- Designing AI Agents with RAG Systems
- Practical Use Cases of RAG + Agent-Based AI Systems
- Scaling AI Systems in Production
- Evaluation Frameworks for RAG + Agent Systems
- Security and Data Isolation Strategies
- Failure Modes and Recovery Patterns
- Enterprise RAG Architecture Best Practices
- How Does the ROI Looks
- Common Pitfalls in AI App Architecture
- The Evolving Landscape of AI System Design
- Conclusion
- About iProgrammer Solutions
- FAQs
Most AI demos can look impressive in isolation. You hit the prompt, a clean answer comes out, and everyone in the room nods. The issues starts when that same setup is expected to work inside a business process. But data is messy. Context is scattered across tools. Users ask vague questions. Compliance teams ask sharper ones.
This is where many promising AI initiatives slow down. Not because the models are weak, but because the surrounding system was never designed for real usage. A production system needs to retrieve the right data, reason over it, act on it, and do so reliably at scale.
That is the difference between a prototype and a production-grade AI app architecture.
Over the past year, two approaches have started to define how serious systems are built. Retrieval-Augmented Generation (RAG) brings grounded, up-to-date context into model responses. Agent-based systems introduce decision-making and task execution. Combined, they form a powerful pattern that moves AI from answering questions to completing work.
This blog breaks down how to design such systems in a way that holds up under real usage. It focuses on practical architecture decisions, not theoretical promise.
RAG is an approach whereby the AI system first retrieves useful pieces of information and then generates a response. In contrast to the model depending exclusively on its existing knowledge, it uses more grounded data from a specific field.
This matters because large language models are not databases. They are probabilistic systems. Lack of grounding could lead to generating responses that look right but are, indeed, incorrect.
This problem can be resolved by designing an effective architecture for the RAG framework. The approach implies introducing a step of retrieving information between the input and response generation.
This approach improves:
- Accuracy, because responses are based on real data
- Freshness, because the knowledge base can be updated
- Control, because you decide what data is used
In production systems, RAG is rarely optional. It becomes the foundation layer of the AI app architecture.
Why RAG Alone Is Not Enough
RAG improves answers, but it does not complete workflows. It retrieves and generates. It does not decide what to do next.
Consider a support system. A user asks about a refund. RAG can fetch policy details and generate a response. But real workflows require more:
- Checking order status
- Validating eligibility
- Triggering a refund request
- Logging the interaction
This is where AI agents come in. They extend the system beyond answering. They introduce planning, tool usage, and multi-step execution. Without them, systems remain informational. With them, they become operational. A production-ready AI system design combines both layers.
Core Components of AI Architecture
A reliable system is built as a set of coordinated layers. Each layer has a clear role. Blurring responsibilities leads to fragile systems.

Here are the essential components:
1. Interface Layer
This is where users interact with the system. It can be a chat interface, API, or embedded workflow.
In production, this layer must handle ambiguity, not just input. Users rarely ask clean questions. The interface should support session memory, input validation, and context persistence. It should also standardize inputs before passing them downstream.
A weak interface layer pushes noise into the system. A strong one reduces unnecessary load on every other layer.
2. Orchestration Layer
This layer manages flow. It decides whether to retrieve data, call an agent, or execute a tool.
In practice, this is where system intelligence begins. It defines pathways, not just steps. Poor orchestration leads to redundant retrieval calls, unnecessary agent loops, and higher latency.
Effective orchestration relies on clear routing logic, fallback paths, and state management across multi-step interactions. It should also remain interpretable. Black-box orchestration becomes difficult to control at scale.
3. Retrieval Layer
This includes vector databases and indexing systems. It powers the RAG architecture.
Its role goes beyond fetching data. It determines what the model is allowed to know in that moment. That makes it one of the most sensitive layers in the system.
A production-grade retrieval layer must support filtering, ranking, and context shaping. It should return information that is both relevant and usable by the model. Poor retrieval does not fail loudly. It quietly degrades output quality.
4. Model Layer
This is the LLM architecture. It handles reasoning, summarization, and generation.
In isolation, models appear capable. In production, their performance depends heavily on input quality and constraints. This layer must be tightly controlled through prompt design, token limits, and structured outputs.
Model selection should be task-specific. Not every step requires a large model. Routing smaller tasks to lighter models improves both speed and cost efficiency.
5. Agent Layer
This handles planning, decision-making, and execution.
Agents introduce stateful behavior into the system. They break down tasks, decide next actions, and interact with tools.
Without guardrails, agents can become unpredictable. Production systems require bounded autonomy. This includes limiting tool access, defining execution depth, and enforcing checkpoints before critical actions.
6. Tooling Layer
This includes APIs, databases, and business systems the AI can interact with.
This is where AI connects to real operations. The quality of this layer determines whether the system can move beyond insights into action.
Each tool integration must be deterministic and well-documented. Ambiguous APIs create cascading failures when invoked by agents. Strong tooling design ensures that every action is predictable and reversible where possible.
7. Monitoring and Feedback
This tracks performance, errors, and user interactions.
In production, visibility is non-negotiable. Systems must capture not just outputs, but the full chain of decisions that led to them.
Monitoring should include retrieval quality, model responses, agent actions, and system latency. Feedback loops should feed into continuous improvement, whether through prompt tuning, data updates, or orchestration changes. Without this layer, systems degrade silently over time.
Each layer must be independently scalable and observable. This separation is critical in enterprise AI systems where reliability is non-negotiable.
Role of AI Agents in Modern Systems
AI agents bring structure to complex tasks. Instead of responding once, they iterate until a goal is achieved.
An agent typically performs:
- Goal interpretation
- Task decomposition
- Tool selection
- Execution
- Reflection and correction
This creates a loop that mimics structured reasoning.
In an AI agents architecture, agents can be:
- Single-agent systems for focused tasks
- Multi-agent systems for complex workflows
For example, in a finance system, one agent retrieves policy data, another validates compliance, and the third executes transactions. This modularity allows systems to scale in capability without becoming chaotic.
Designing the Retrieval Layer (Vector DBs)
The retrieval layer is where many systems fail quietly. Poor retrieval leads to poor outputs, regardless of model quality.
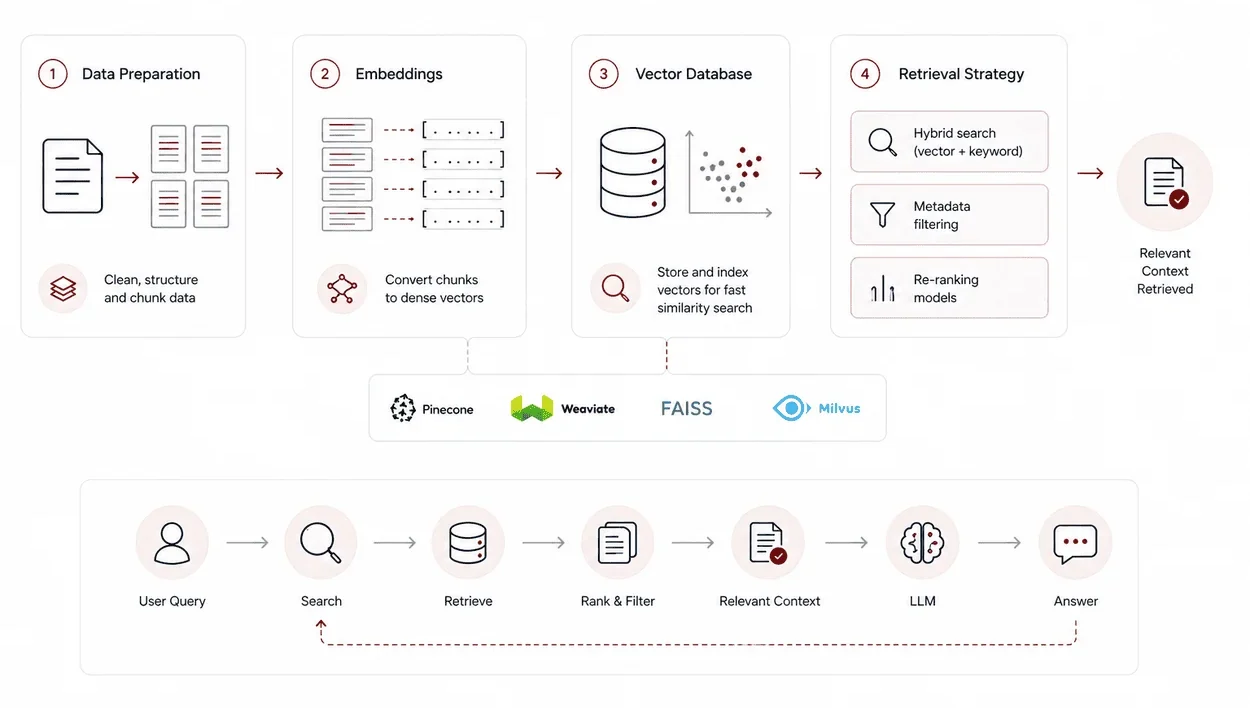
A strong retrieval design focuses on three areas:
Data Preparation
Raw data must be cleaned, structured, and chunked. Chunk size matters. Too small loses context. Too large reduces relevance.
Embeddings
Choosing the right embedding model affects retrieval accuracy. Domain-specific embeddings often perform better.
Vector Database
The database must support fast similarity search and filtering. Popular options include:
Retrieval Strategy
Basic similarity search is rarely enough. Production systems use:
- Hybrid search (vector + keyword)
- Metadata filtering
- Re-ranking models
Retrieval Design Best Practices
| Component | Best Practice | Common Mistake |
|---|---|---|
| Data Chunking | Context-aware segmentation | Fixed-size arbitrary chunks |
| Embeddings | Domain-tuned models | Generic embeddings for all data |
| Search Strategy | Hybrid + re-ranking | Pure vector similarity |
| Metadata Use | Rich tagging for filtering | Ignoring metadata |
| Refresh Strategy | Incremental updates | Static knowledge base |
Context Engineering and Token Management
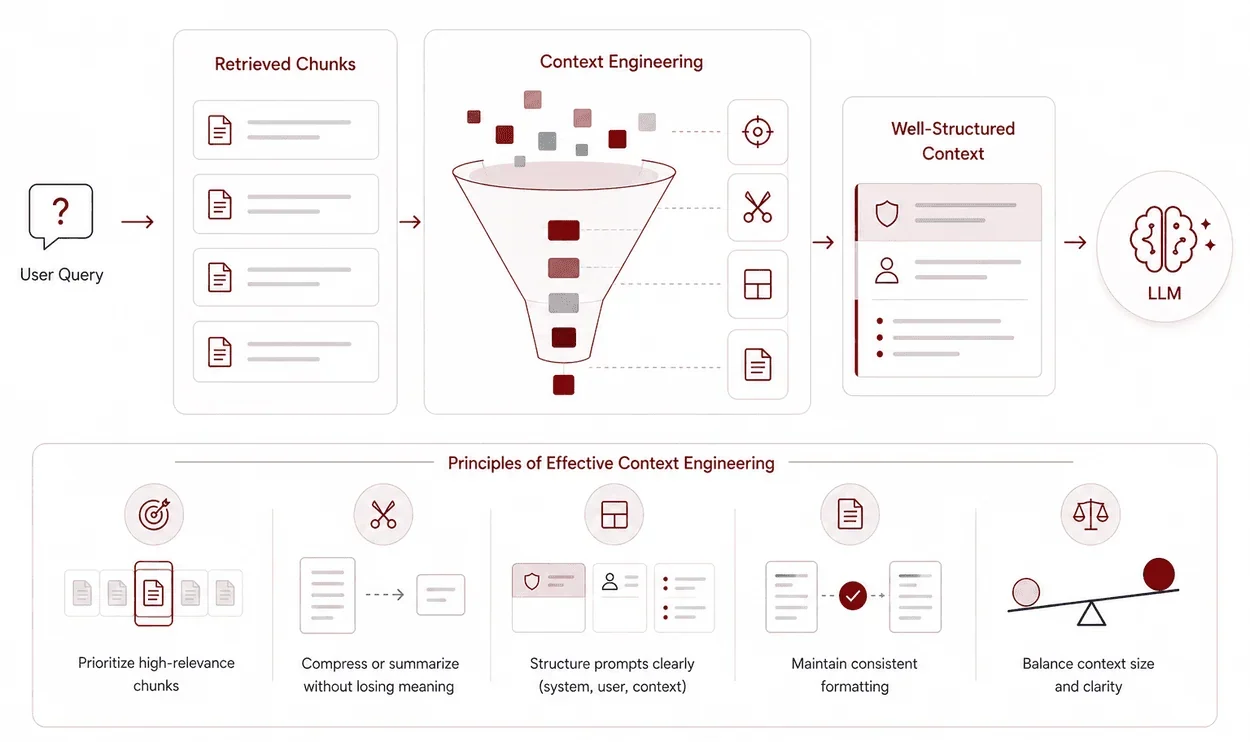
Retrieval does not directly improve outputs. What matters is how retrieved data is shaped before it reaches the model. This is where context engineering becomes critical.
Large language models operate within strict token limits. Every token used has a cost and an impact on performance. Poor context design leads to irrelevant or diluted responses, even when retrieval is accurate.
A production system must decide what context to include, what to exclude, and how to structure it. This involves:
- Prioritizing high-relevance chunks instead of passing everything retrieved
- Compressing or summarizing content without losing critical meaning
- Structuring prompts to clearly separate system instructions, user input, and retrieved context
- Maintaining consistency in formatting so the model can interpret context reliably
There is also a trade-off between context size and clarity. Adding more data does not guarantee better answers. In many cases, it introduces noise that weakens reasoning.
Another consideration is dynamic context building. Not every query requires the same amount or type of information. Systems should adapt context size and structure based on the task.
Well-designed context engineering ensures that the model works with precise, relevant input instead of raw data. This layer quietly determines the quality of every response.
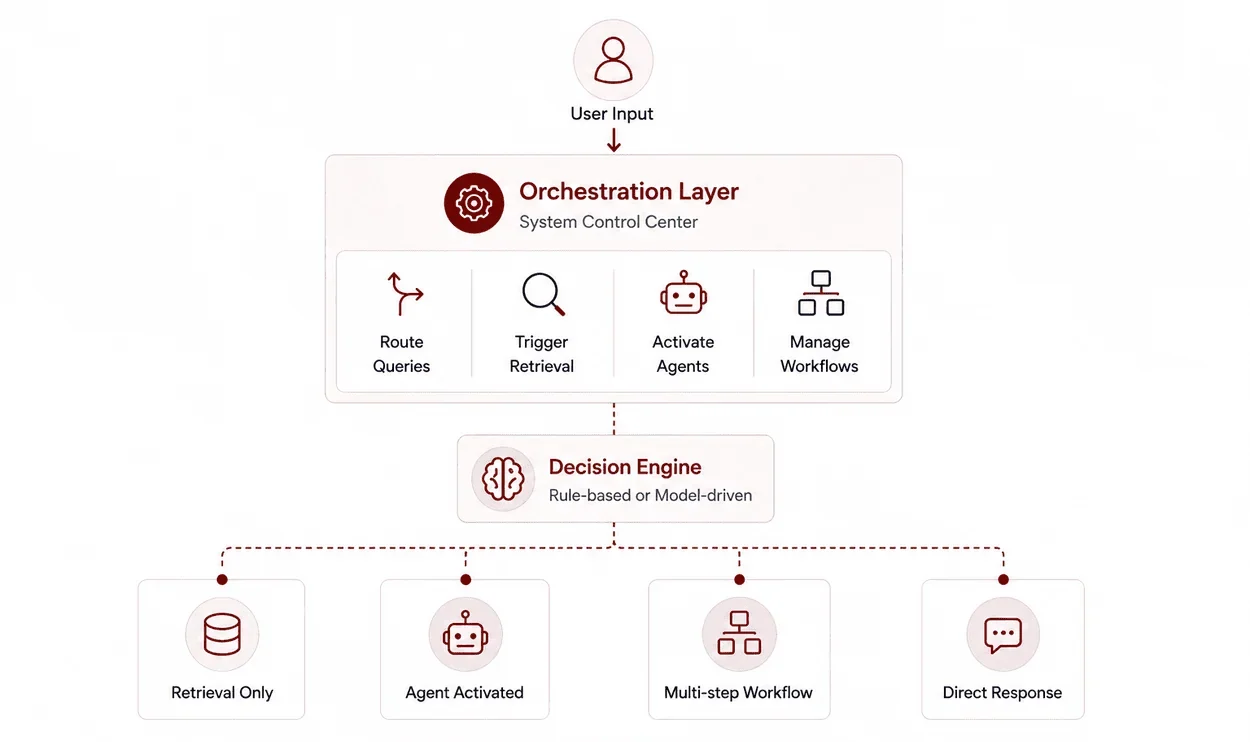
The orchestration layer acts as the system’s control center. It determines what happens after a user input.
This includes:
- Routing queries
- Triggering retrieval
- Activating agents
- Managing multi-step workflows
Decision engines within this layer can be rule-based or model-driven.
A good orchestration design avoids unnecessary complexity. Not every query needs an agent. Some only require retrieval.
Over-engineering here leads to latency and cost issues.
Designing AI Agents with RAG Systems
Combining agents with RAG requires careful coordination.
The key challenge is context management. Agents must know when to retrieve and how to use retrieved data.
A typical flow looks like this:
- User submits a query
- System retrieves relevant context
- Agent evaluates the task
- Agent decides next steps
- Tools are invoked if needed
- Final response is generated
This creates a feedback loop where retrieval informs decisions, and decisions trigger further retrieval.
The design must ensure:
- Retrieval is not repeated unnecessarily
- Context remains consistent across steps
- Costs remain predictable
This integration defines a mature AI app architecture.
Practical Use Cases of RAG + Agent-Based AI Systems
Production systems are defined by where they deliver consistent value. RAG with agents works best in workflows that require both context and action.
Customer Support Automation
Support teams deal with scattered knowledge and repetitive queries. RAG retrieves accurate policy and order data. Agents handle workflows like validating eligibility, initiating refunds, and updating tickets. This improves resolution quality while reducing manual effort.
Internal Knowledge Assistants
Enterprise knowledge is spread across documents and tools. Access is slow and inconsistent. RAG enables retrieval across sources. Agents summarize, generate insights, and trigger actions based on user intent. This turns static knowledge into a usable system.
Finance and Compliance Workflows
Accuracy and traceability are critical in finance operations. RAG grounds responses in policy and regulatory data. Agents validate transactions, flag anomalies, and generate audit-ready outputs. This reduces risk without slowing down processes.
IT Operations and Incident Management
IT teams manage large volumes of logs and recurring issues. RAG retrieves relevant incidents and documentation. Agents diagnose issues, suggest fixes, and execute predefined actions. This reduces response time and improves consistency.
Sales and Pre-Sales Enablement
Sales teams rely on fragmented product and customer data. RAG pulls relevant information quickly. Agents generate proposals, answer queries, and surface deal insights. This improves speed without compromising accuracy.
Operations and Workflow Automation
Many business processes involve repetitive, multi-step tasks. RAG provides the required context. Agents validate inputs, execute actions, and update systems. This shifts AI from assistance to execution.
Scaling AI Systems in Production
Scaling is not just about handling more users. It involves managing complexity, latency, and cost. Key considerations include:
|
Latency Optimization
Users expect near real-time responses. Techniques include:
|
Cost Management
LLM usage can become expensive. Strategies include:
|
System Reliability
Failures must be handled gracefully. This includes:
|
Scaling Considerations
| Area | Strategy | Impact |
|---|---|---|
| Latency | Caching and parallel execution | Faster responses |
| Cost | Model routing and token control | Reduced operational cost |
| Reliability | Fallbacks and retries | Higher system uptime |
| Throughput | Load balancing | Stable performance |
| Observability | Logging and tracing | Better debugging |
Evaluation Frameworks for RAG + Agent Systems
Once a system is deployed, the focus shifts from “does it work” to “how well does it work under real usage.” Evaluation frameworks provide that clarity.
Unlike traditional systems, AI outputs are not strictly deterministic. This makes evaluation more complex. Measuring only final responses is not enough, especially in multi-step agent workflows.
A strong evaluation approach considers multiple layers:
- Retrieval quality, measured through relevance and coverage of returned data
- Response quality, evaluated for correctness, completeness, and grounding
- Task success rate, especially for agent-driven workflows
- Latency and cost per interaction
Evaluation should happen in two stages. Offline testing uses curated datasets and known queries to benchmark performance. Online evaluation captures real user interactions and uncovers edge cases.
Another important aspect is groundedness. Responses should be traceable to retrieved data, not just plausible in language. Systems that sound correct but lack source alignment create long-term risk.
Human review still plays a role, especially for high-impact use cases. Automated scoring helps scale evaluation, but it cannot fully replace judgment in complex scenarios.
A production system improves only when it is measured consistently. Without structured evaluation, performance issues remain hidden until they affect users directly.
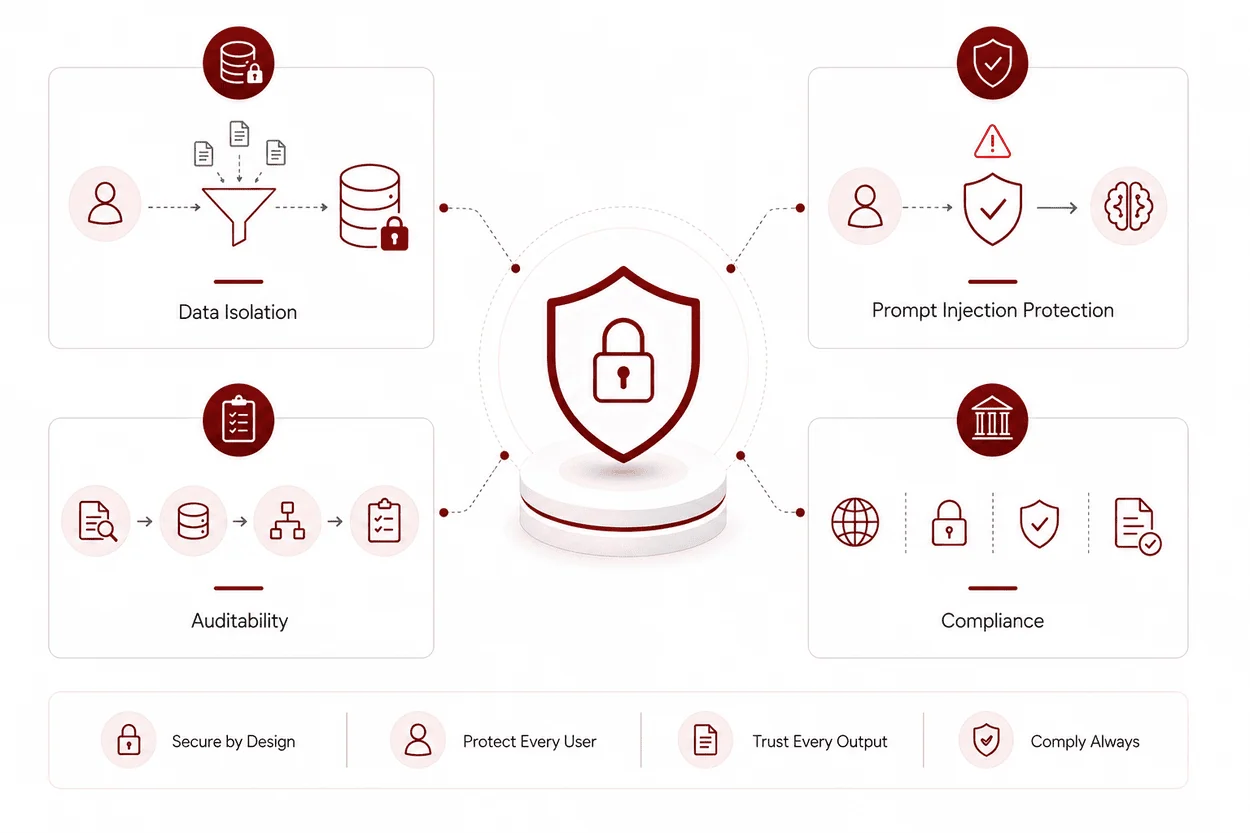
Security becomes critical when AI systems interact with sensitive data. Key areas to address:
Data Isolation
Ensure users only access permitted data. This requires:
- Role-based access control enforced at every layer, not just the interface
- Context-aware filtering in the retrieval layer to prevent cross-tenant leakage
- Separation of indexes or namespaces for sensitive datasets
Weak isolation often does not fail visibly. It surfaces as subtle data leaks across users or roles.
Prompt Injection Protection
Malicious inputs can manipulate system behavior, especially in agent-driven workflows. Safeguards include:
- Input validation to detect unsafe or irrelevant instructions
- Context sanitization before passing retrieved data to the model
- Strict separation between system instructions and user-provided input
Without these controls, agents can be tricked into executing unintended actions.
Auditability
Every action must be traceable. This is critical for debugging and compliance. Logs should capture:
- User queries and session context
- Retrieved documents and sources
- Model responses and intermediate steps
- Actions executed by agents or tools
A system that cannot explain its output cannot be trusted in production environments.
Compliance
Systems must align with regulations such as GDPR or HIPAA where applicable. This includes:
- Data residency controls based on region
- Secure storage and encryption of sensitive information
- Controlled retention and deletion policies
- Clear boundaries on how data is used for model interaction
Compliance should be designed into the system, not added later as a patch.
Failure Modes and Recovery Patterns
Production systems do not fail in obvious ways. They fail in layers, often producing outputs that appear reasonable but are incorrect or incomplete. Understanding these failure modes is critical for designing reliable systems.
Common failure types include:
- Retrieval failure, where relevant data is not found or ranked correctly
- Reasoning failure, where the model misinterprets context or draws incorrect conclusions
- Tool failure, where APIs return errors or unexpected results
- Orchestration failure, where the system chooses the wrong execution path
Each of these requires a different recovery strategy. Treating all failures the same leads to inefficient or ineffective handling.
Effective recovery patterns include:
- Retrying retrieval with modified queries or relaxed filters
- Falling back to simpler flows when agent execution becomes uncertain
- Validating outputs before triggering critical actions
- Escalating to human intervention for high-risk scenarios
Another important practice is confidence estimation. Systems should detect when outputs are uncertain and adjust behavior accordingly, rather than proceeding blindly.
Failure handling should be built into the architecture, not added later. Systems that assume perfect execution tend to break under real-world conditions.
In production, reliability is not defined by avoiding failure. It is defined by how consistently the system recovers from it.
Enterprise RAG Architecture Best Practices
Building for enterprise use requires discipline in design. Early shortcuts often become long-term constraints.
Key practices include:
- Keep retrieval independent from model logic to allow updates without retraining
- Use modular agents with defined responsibilities instead of monolithic workflows
- Monitor outputs continuously to detect drift, hallucinations, or failures
- Design for failure with fallback paths and controlled degradation
- Avoid unnecessary orchestration complexity that increases latency and cost
In addition, standardization plays a critical role. Consistent data schemas, prompt structures, and API contracts reduce variability across the system.
Many teams try to solve everything in a single step. This leads to brittle systems that are hard to scale or debug. A layered approach ensures flexibility and long-term stability.
How Does the ROI Looks
Production systems are evaluated by outcomes, not capability. ROI in RAG and agent-based systems is visible across efficiency, accuracy, and scalability.
- Reduced manual effort
Automates repetitive, multi-step tasks across support, operations, and internal workflows - Lower error rates
Grounds decisions in real data and enforces structured execution paths - Faster turnaround times
Eliminates delays in information retrieval and decision-making - Scalable operations
Handles increased workload without proportional increase in headcount - Improved consistency
Standardizes outputs across users, teams, and processes - Better resource allocation
Frees teams to focus on high-value work instead of routine tasks - Predictable cost per interaction
Enables controlled scaling through model routing and optimized usage
To measure impact effectively, track:
- Time saved per workflow
- Reduction in manual interventions
- Output accuracy and consistency
- Cost per interaction vs traditional processes
Common Pitfalls in AI App Architecture
Even well-funded teams run into predictable issues. These are rarely technical limitations. They are design oversights.
- Over-reliance on a single model, which creates bottlenecks and limits flexibility
- Poor data quality in retrieval systems, leading to misleading or incomplete outputs
- Lack of monitoring and feedback loops, causing silent performance degradation
- Ignoring user behavior patterns, resulting in systems that do not match real usage
- Treating AI as a feature instead of a system, which leads to weak integration
Another common issue is premature scaling. Teams optimize for volume before stabilizing accuracy and control. This increases cost without improving outcomes.
Each of these can derail an otherwise strong implementation.
The Evolving Landscape of AI System Design
The pace of change in this space is high. New models, tools, and frameworks appear frequently.
What is changing is the tooling layer and model capabilities. What remains stable is how systems need to be structured to work reliably.
Core principles still apply:
- Ground outputs with real data through strong retrieval design
- Structure workflows with agents to handle multi-step tasks
- Design systems as layered architectures, not isolated features
Emerging trends are shaping how these principles are implemented:
- Multi-agent systems coordinating specialized tasks
- Tool orchestration frameworks that standardize execution flows
- Hybrid retrieval models combining semantic and structured search
- Smaller, task-specific models reducing dependency on large general models
Adopting these trends without a solid foundation often leads to rework. Systems built on clear architectural principles can evolve without disruption.
Designing production-grade systems requires more than choosing the right model. It demands a thoughtful combination of retrieval, reasoning, and execution.
RAG ensures that systems are informed. Agents ensure that systems are capable. Together, they form a practical approach to building reliable AI solutions.
A well-structured AI app architecture is not just a technical asset. It becomes a competitive advantage. It allows businesses to move faster, reduce errors, and deliver consistent outcomes.
About iProgrammer Solutions
At iProgrammer Solutions, building scalable and reliable AI systems is a core focus. The approach goes beyond experimentation and focuses on real-world deployment.
From designing robust LLM architecture to implementing production-ready systems, the team works closely with businesses to translate AI potential into measurable outcomes.
Explore our AI development services and Product engineering capabilities to see how structured AI solutions are built for scale.
1. How do you evaluate the performance of a RAG system?
2. Can RAG systems work without vector databases?
3. What is the role of fine-tuning in RAG-based systems?
4. Are multi-agent systems always better than single-agent setups?
5. How often should the knowledge base in a RAG system be updated?
