





Drift Detection in AI Applications

- What Drift Detection Really Means in Production
- Types of Drift in Modern AI Systems
- Data vs Model vs Prompt Drift: A Practical View
- Why Drift Detection Fails in Many Organizations
- Data Quality vs Drift: Where Signals Get Misinterpreted
- Key Metrics for Drift Detection
- Drift Detection Metrics at a Glance
- Drift Thresholding: When Is Drift Actionable?
- How to Detect Drift in AI Models in Production
- Architecture for Drift Detection
- Building a Drift Detection Pipeline
- Handling Drift in Production
- Shadow Deployments and Controlled Model Validation
- Tools for Drift Detection
- AI Observability and Drift Detection Best Practices
- Connecting Drift Detection to Modern AI Architectures
- The Real Cost of Ignoring Drift
- Failure Modes of Drift Detection Systems
- A More Grounded Way to Think About Drift
- Final Thoughts
- About iProgrammer
- FAQ
If you ask a product owner why a recommendation system changed its behavior, the answer often traces back to a release, a campaign, or a shift in user traffic. If you ask the same question about the model itself, and the answers get vague. It was working. Then it wasn’t as consistent. Then people stopped relying on it as much.
The uncomfortable part is that the model did not suddenly break. It kept learning from a version of the world that no longer exists. This gap between what the model “knows” and what the business is actually dealing with is where most production issues begin.
Drift sits exactly in that gap. It is not just a technical phenomenon tied to changing data distributions. It highlights the fast pace of real-life systems against the slow adaptation of models.
It poses a unique challenge for AI practitioners deploying their models in a production environment. You are not just managing model performance. You are managing the relevance of decisions powered by that model.
This is where drift detection in AI becomes foundational. Not as a monitoring checkbox, but as a way to continuously reconcile what the model believes with what the business is experiencing.
What Drift Detection Really Means in Production
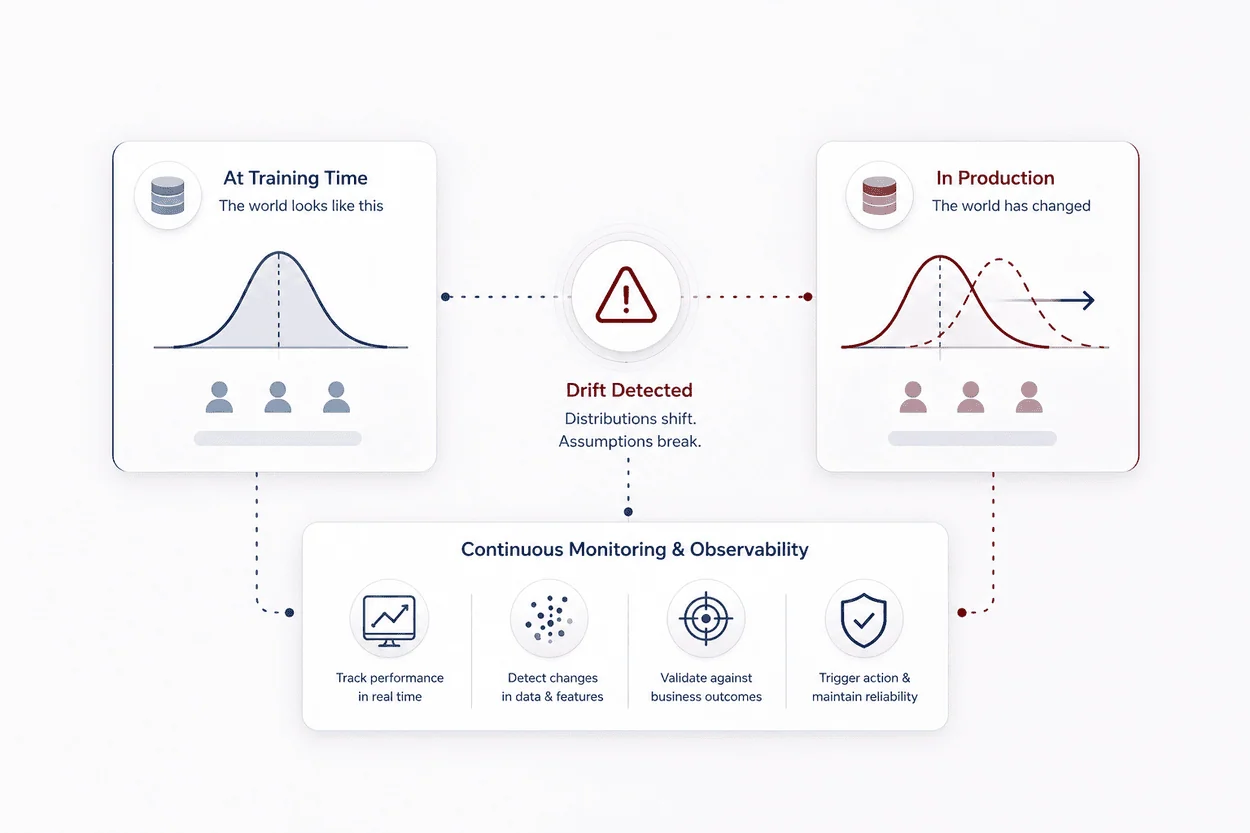
On the surface, model drift may seem like detecting any discrepancy between the expected model behavior and its actual performance because of variations in the data or environment. While that may be true, there is much more to it.
In production systems, drift is not just about statistical change. It is about broken assumptions. Every model is trained on a snapshot of the world. That snapshot includes user behavior, data distributions, feature relationships, and labeling logic. With time, these underlying assumptions become invalid.
Drift detection, therefore, is the practice of continuously validating whether those assumptions still stand. It answers questions like:
- Are users behaving differently than before?
- Are features showing new patterns?
- Are predictions still aligned with business outcomes?
This is why drift detection in AI is tightly linked to ML observability. It is not just about catching anomalies. It is about understanding system behavior in context.
Types of Drift in Modern AI Systems
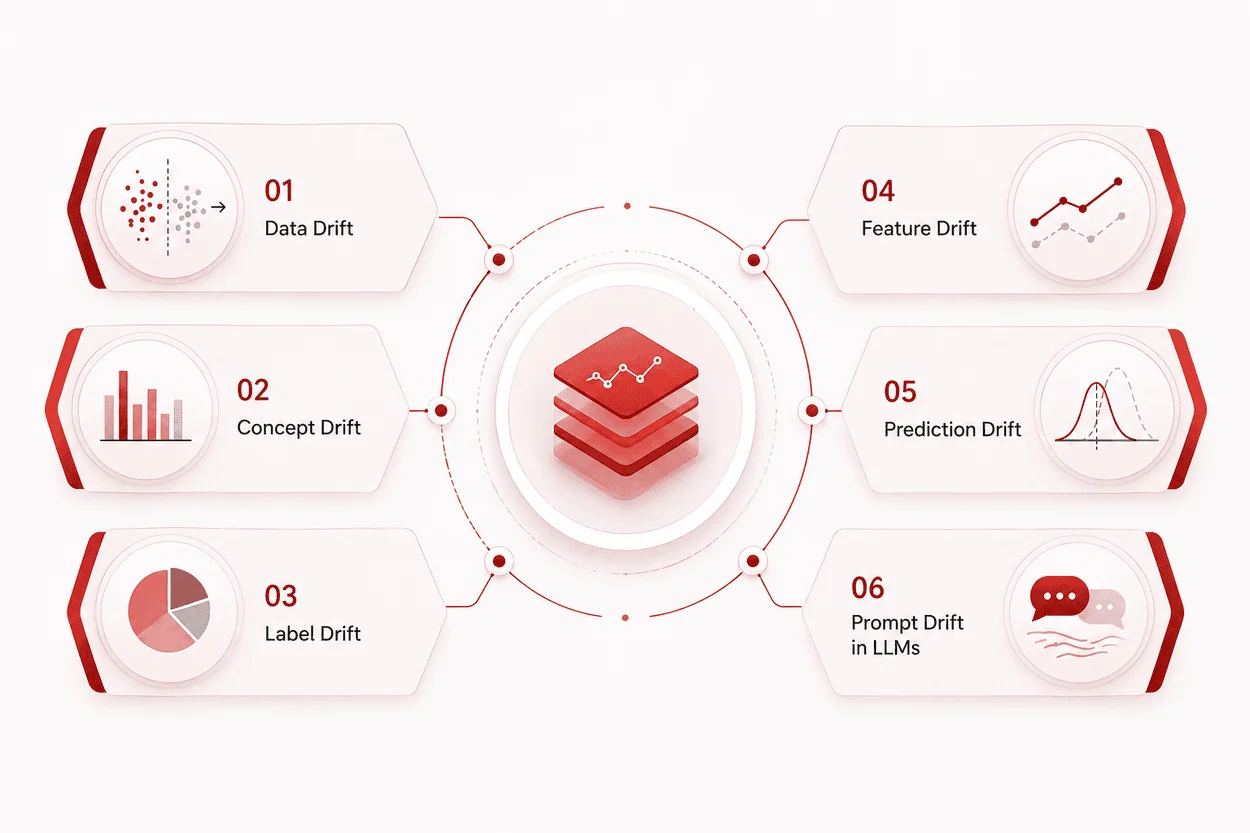
Most explanations stop at concept and data drift. In practical situations, model drift comes into effect in much more complicated manners.
1. Data Drift (Covariate Shift)
This happens when input data varies while the relation with the target remains stable.
For example, a recommendation engine faces an increase in new product categories in festive times. It still knows about the user’s preferences, but its input space has changed.
This is where data drift detection becomes critical. It focuses on identifying distribution shifts across features.
2. Concept Drift
Here, the relationship between input features and output changes.
Example: Fraud patterns evolve. Transactions that were once safe may now indicate risk.
This type of drift is harder to detect because input distributions may look stable while outcomes degrade.
3. Label Drift
The distribution of target labels changes over time.
Example: Customer sentiment models trained on past language patterns struggle with new slang or cultural references.
4. Feature Drift
Individual features shift in importance or behavior.
Example: A logistics model relies heavily on fuel prices. Sudden volatility changes its predictive weight.
5. Prediction Drift
Even without visible data changes, model outputs begin to skew. This often signals deeper issues in training data or hidden biases.
6. Prompt Drift in LLMs
Modern AI systems introduce a new layer. Prompt behavior. Prompt drift in LLMs happens when the efficiency of prompts declines because of contextual shifts, intent modifications, or any internal model adjustments.
Example: The assistant working in customer care begins providing imprecise responses based on evolving user queries.
This sort of drift is not easily noticeable and needs close observation of the input and output semantically.
| Drift Type | What Changes | Where It Appears | Detection Complexity | Business Impact |
|---|---|---|---|---|
| Data Drift | Input distribution | Feature pipelines | Moderate | Medium |
| Model Drift | Prediction accuracy | Output layer | High | High |
| Prompt Drift | Input-output alignment in LLMs | Interaction layer | High | High |
This distinction matters because detection strategies differ. Treating all drift the same leads to wasted effort and missed signals.
Why Drift Detection Fails in Many Organizations
Before discussing techniques, it is worth examining a flawed assumption. Many teams believe drift detection is a tooling problem. It is not. It is a systems thinking problem.
Assumption 1: Statistical Change Equals Business Impact
Not all drift matters. A feature distribution may shift without affecting outcomes. Following all of the signals produces noise and makes teams desensitized to what really matters. The skeptic’s point would be that most drift notifications are usually ignored due to lack of context. Without a clear link to model performance or business KPIs, statistical shifts rarely justify action.
Assumption 2: Monitoring Accuracy Is Enough
Accuracy drops are lagging indicators. By the time you notice them, the damage is done. In practice, there are always delays and inconsistencies in labeling, so real-time accuracy cannot be guaranteed. Models may fail to perform in production while being stable in historical benchmarks.
Assumption 3: One Detection Method Fits All
Different models require different strategies. A fraud model behaves differently from a recommendation engine. Utilizing only one detection approach fails to take into account the behavior of models. The thresholds and metrics should correspond to the model’s sensitivity and business needs, otherwise signals are either too noisy or insufficient.
Assumption 4: Drift Is a Model Problem
Often, drift originates in upstream data pipelines, product changes, or user behavior shifts. Changes in data collection or user interaction can surface as model issues. This is why model drift monitoring must extend beyond the model to the full data and product pipeline.
Data Quality vs Drift: Where Signals Get Misinterpreted
Not all drift signals indicate a change in real-world behavior. Many originate from data quality issues.
- Data schema shifts, missing records, delayed ingestion, or transformation errors may introduce patterns similar to drift. Without thorough validation, these problems may be confused for model degradation.
- This creates a false response loop. Teams retrain models when the actual problem lies in upstream pipelines. This leads to wastage of resources, and in some instances, reduced efficiency.
- It is imperative that one differentiates between data quality checks and drift detection. Data validation checks should run before drift analysis. Only when data integrity is confirmed should drift signals be evaluated for model impact.
When all outliers are treated as drifts, it becomes difficult to understand what is happening. Being able to differentiate will increase efficiency and effectiveness.
Key Metrics for Drift Detection
Effective drift detection relies on a mix of statistical and performance metrics.
| Metric Category | Key Metrics | Description |
|---|---|---|
| Distribution-Based Metrics |
|
These measure how much data has shifted. |
| Performance Metrics |
|
These indicate impact on predictions. |
| Business Metrics |
|
These connect drift to real outcomes. |
| Embedding and Semantic Metrics (for LLMs) |
|
These help track prompt drift in LLM-driven systems. |
Drift Detection Metrics at a Glance
| Metric Type | Example Metrics | Best Use Case | Limitation |
|---|---|---|---|
| Statistical | KS Test, PSI | Detecting input shifts | No direct business context |
| Performance | Accuracy, Recall | Measuring prediction quality | Delayed signal |
| Business | Revenue, Conversion | Measuring real impact | Hard to attribute |
| Semantic | Embedding similarity | LLM monitoring | Requires advanced setup |
Drift Thresholding: When Is Drift Actionable?
Detection of drift alone is not sufficient. One needs to determine whether there is any significant drift.
- Not every deviation requires intervention. Small changes might be within normal variability, particularly in an ever-changing environment. Responding to all cues would result in superfluous relearning and unnecessary noise.
- Thresholds should be set based on context. Local thresholds would enable detecting local changes, while global thresholds would facilitate monitoring system-wide changes. More importantly, thresholds should reflect business risk. A minor shift in a high-impact model may require immediate action, while larger shifts in low-risk systems may not.
- Static thresholds frequently prove ineffective in production environments. Adaptive thresholds, which utilize historical variance and seasonality, serve as more accurate indicators.
Drift is continuous, but intervention is not. The capability of discerning between signal and noise is what gives detection its value.
How to Detect Drift in AI Models in Production
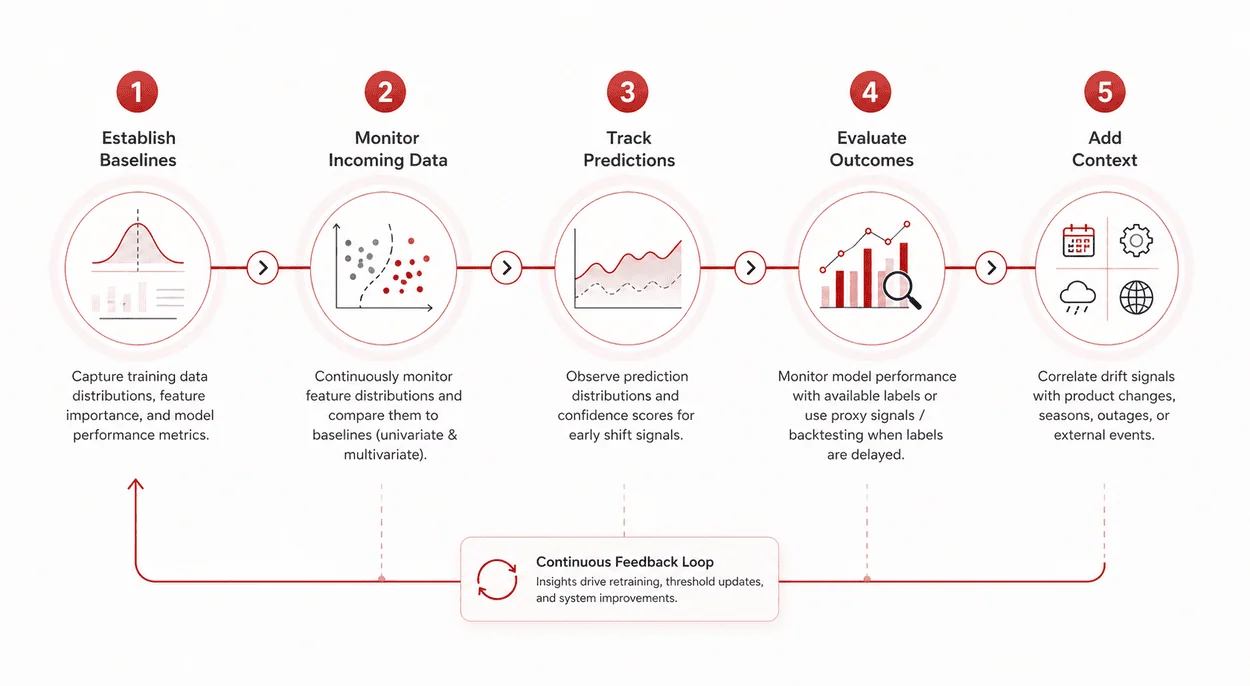
Detection is not a single step. It is a layered process.
Step 1: Establish Baselines
Collect training data distributions, feature significance, and metrics for model performance. Summary statistics, feature correlations, and anticipated output values should also be considered.
Without a baseline, there is nothing for drift to compare itself against. However, even more crucially, inadequate baselines result in erroneous detections.
Step 2: Monitor Incoming Data
Monitor feature distributions continuously and compare them to past baselines.
Pay attention not only to univariate drifts but also to multivariate drifts. Certain features might remain constant when observed independently but undergo changes when observed collectively.
Step 3: Track Predictions
Observe predictions and probabilities of being correct.
Shifts in prediction confidence often surface before accuracy drops. These indicators can help understand whether the system starts to become overconfident or uncertain under new circumstances.
Step 4: Evaluate Outcomes
In case of having any labeled data, constantly monitor its performance based on selected metrics.
In delayed feedback systems, use proxy signals or backtesting to estimate performance. Focusing solely on actual labels will result in blind spots.
Step 5: Add Context
Connect observed drift signals with product updates, seasons, upstream problems, or external events.
Without any context, drift identification is reactive. With context, it becomes diagnostic. This layered approach is the foundation of AI monitoring systems that actually work.
Architecture for Drift Detection
A production-grade drift detection architecture typically includes:
- Data ingestion layer
- Feature store
- Monitoring service
- Alerting system
- Retraining pipeline
Each component must operate with consistent data contracts and versioning.
The key is integration. Drift detection cannot operate in isolation. It must connect with data engineering, MLOps pipelines, and business analytics systems to provide actionable signals.
Building a Drift Detection Pipeline
A robust pipeline includes:
- Data collection from live systems with proper sampling and logging
- Feature extraction and transformation aligned with training logic
- Statistical comparison with baseline using appropriate tests
- Performance evaluation with both real and proxy metrics
- Alert generation with thresholding and prioritization
- Automated or manual retraining with validation checkpoints
The challenge is not building this pipeline. It is maintaining consistency between training and production environments while scaling across multiple models.
Handling Drift in Production
Detection is only half the problem. Response determines whether systems remain reliable.
Common Strategies
- Scheduled retraining based on data refresh cycles
- Trigger-based retraining driven by drift thresholds
- Ensemble models to balance stability and adaptability
- Online learning for continuous updates in dynamic environments
Each comes with trade-offs in stability, cost, and risk.
Blind retraining can amplify bias if incoming data is skewed or incomplete. A more disciplined approach validates data quality, checks feature integrity, and evaluates model performance before deployment. Retraining should be controlled, not reactive.
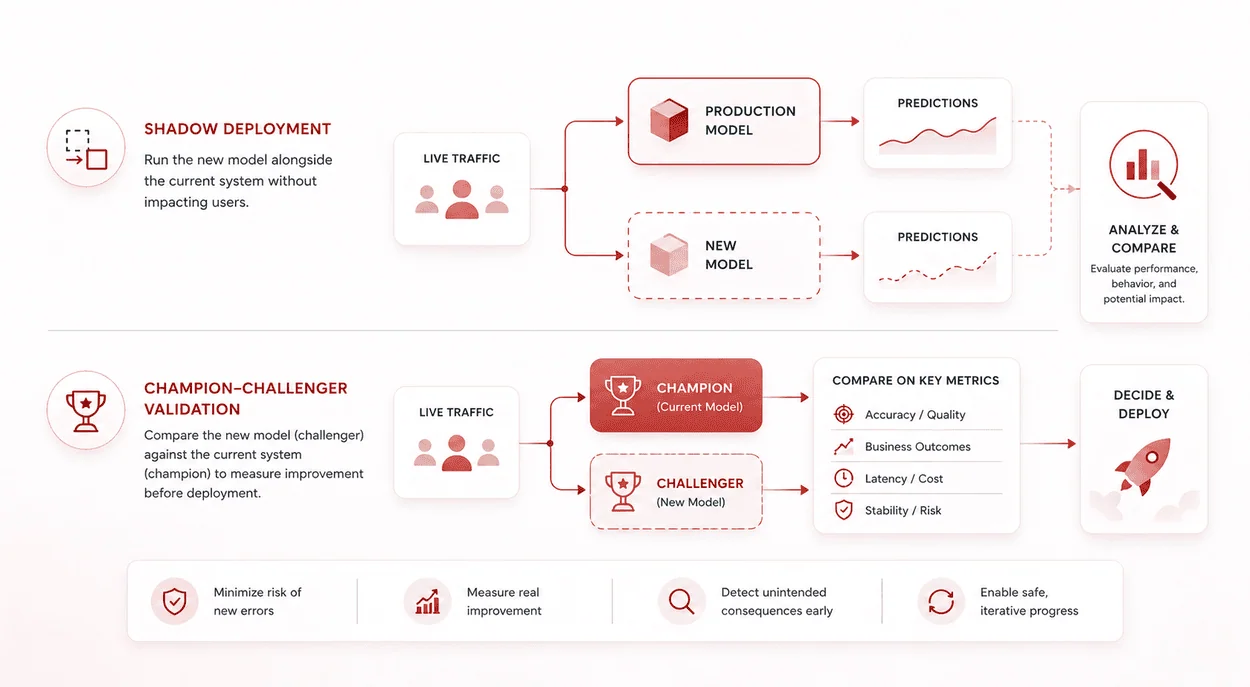
Retraining a model is only part of the response. Verification of its real-life performance is just as crucial.
- Shadow testing involves running newly developed models simultaneously with the current system in place. This provides an opportunity to test performance, analyze behavior, and recognize any unintended effects prior to deployment.
- Champion challenger method takes this concept further. In this case, the current system stays in use, whereas the newly developed one is tested against the former. Different aspects of its performance can be compared.
This controlled validation reduces the risk of introducing new errors while addressing drift. It also provides a structured way to measure improvement rather than assuming it. In production systems, safe iteration matters as much as detection.
Tools for Drift Detection
Several tools support drift detection workflows:
- Evidently AI for statistical monitoring and reporting
- NannyML for performance estimation without labels
- MLflow for model tracking and lifecycle management
- Cloud-native tools like Azure Monitor and Vertex AI for integrated monitoring
These tools provide visibility and automation, but they do not replace sound monitoring strategy or domain understanding.
AI Observability and Drift Detection Best Practices
Strong systems share a few common traits:
- Monitoring is tied to business metrics, not just statistical thresholds
- Alerts are contextual and prioritized based on impact
- Drift signals are correlated across data, model, and product layers
- Retraining pipelines are controlled, versioned, and auditable
This is where ML observability becomes central. It ensures visibility across the entire lifecycle, from data ingestion to decision outcomes.
Connecting Drift Detection to Modern AI Architectures
With the rise of LLMs and retrieval-based systems, drift detection has expanded beyond structured data.
Systems built on retrieval pipelines must monitor:
- Query patterns and intent shifts
- Retrieved document relevance and freshness
- Response quality and grounding consistency
These systems introduce dependencies on external and dynamic data sources, making drift more frequent and harder to isolate.
The Real Cost of Ignoring Drift
It is tempting to treat drift as a technical concern. That view does not hold under scrutiny.
Drift impacts:
- Revenue through degraded predictions and missed opportunities
- Compliance through inconsistent or biased decisions
- Customer trust through unreliable system behavior
The cost is rarely immediate. It accumulates quietly until it becomes difficult to isolate or reverse.
Failure Modes of Drift Detection Systems
Drift detection systems are not immune to failure. In many cases, the monitoring layer introduces its own set of challenges.
- Alert fatigue is one of the most common issues. When systems generate frequent, low-impact alerts, teams begin to ignore them. Over time, critical signals are missed.
- Overly sensitive detection can also lead to unnecessary retraining, increasing cost and instability. On the other hand, coarse thresholds may fail to capture meaningful shifts until performance is already affected.
- Another failure mode is misalignment between teams. Data scientists, engineers, and business stakeholders often interpret drift signals differently. Without shared context, responses become inconsistent.
Drift detection is only as effective as the system around it. Poor calibration, lack of ownership, and weak integration can reduce its value, even if the underlying methods are sound.
A More Grounded Way to Think About Drift
Instead of asking, “Is there drift?”
Ask:
- What assumptions did this model make during training?
- Which of those assumptions are no longer valid in production?
- How quickly can we detect, diagnose, and respond to that change?
This shift moves drift detection from a reactive task to a continuous validation process. It leads to systems that remain aligned with real-world conditions.
Drift is not an edge case. It is the default state of any real-world AI system. Models do not fail because they were poorly built. They fail because the world changes faster than they adapt.
Drift detection is how teams stay aligned with that change. It connects data, models, and business outcomes into a single feedback loop.
Organizations that invest in this capability build systems that remain reliable, explainable, and scalable. Those that do not eventually rely on intuition over intelligence.
At iProgrammer, we work with organizations that have moved beyond experimentation and are scaling AI in production.
Our focus is not just on building models, but on sustaining them. That includes designing monitoring pipelines, implementing drift detection frameworks, and ensuring long-term model reliability.
We approach AI as a system, not a feature. That perspective helps our clients maintain performance even as their environments evolve. If you’re evaluating how to strengthen model reliability or implement drift detection in your AI systems, connect with our team to explore a structured, production-ready approach.
1. Can drift detection work without labeled data?
2. How often should models be retrained to handle drift?
3. Is drift detection necessary for small-scale AI systems?
4. How does drift detection differ from anomaly detection?
5. What role does human oversight play in drift management?
